Benchmarks are getting pricier, but expiring faster
Building modern LLM benchmarks is increasingly expensive. It now routinely requires domain experts and careful verification, e.g., Glazer et al., 2024 required IMO gold medalists and a Fields Medalist, while Phan et al., 2025 recruited over 1,000 experts across 50 countries. The problem is that the value of this work can diminish quickly once a benchmark becomes public. If answers leak into training data (accidentally or intentionally), test performance becomes a measure of memorization rather than capability.
The standard mitigation is to keep the test set private and run evaluation behind a server: participants submit models or predictions, and organizers return a score. That helps, but the underlying problem remains. If the same private set is queried repeatedly, the score itself becomes a training signal. Over enough iterations, optimization methods can overfit to this hidden set without ever seeing instance-level labels, a.k.a. leaderboard hacking.
CapBencher is a simple protocol that makes it possible to publish benchmarks openly without fully disclosing the true answers, while turning contamination into something you can detect from the final aggregate accuracy alone. It can also be applied in private evaluation settings by turning such feedback-loop overfitting into a detectable above-cap signal.
The core idea: build a benchmark with a ceiling
In an ordinary, well-defined benchmark, the best possible accuracy is 100%. CapBencher intentionally caps the achievable accuracy below 100%, even for a fully capable model. Before publishing, we modify each problem so that it has multiple answers that are all logically acceptable. Then we pick one of those acceptable answers at random and freeze it as the benchmark label. A model that genuinely solves the underlying problem still faces one extra obstacle: it cannot know which acceptable answer was selected. That extra uncertainty creates a hard ceiling on achievable accuracy. Note that this may sound labor-intensive, but the entire procedure can be fully automated.
This ceiling is a classic concept in statistical machine learning: Bayes accuracy. Informally, Bayes accuracy is the best possible accuracy any predictor could achieve. If the labels contain genuine randomness, even an ideal predictor cannot be correct all the time. CapBencher deliberately introduces a small, controlled amount of label randomness. Crucially, it does so without making the labels incorrect. The modified answers remain logically valid, and the benchmark stays meaningful.
If each question has \(L\) equally likely acceptable answers and we choose the published label uniformly, then the Bayes accuracy is \(1/L\). With \(L=2\), the cap is 50%; with \(L=4\), it’s 25%. If a model is evaluated on the public benchmark and scores above the cap, the most plausible explanation is that the model had access to the realized labels (contamination), or that it effectively learned them through repeated interaction with a private evaluation server (gaming). We flag contamination/gaming when the observed score is significantly above the Bayes accuracy under a one-sided exact binomial test.
The protocol
CapBencher is meant to be lightweight to implement, and can be automatically applied for most standard benchmarks. For each question \(x\), you define a small set of acceptable answers \(F(x)\) and a distribution over that set. You then sample one “realized” answer from \(F(x)\) using an external random number generator and publish only the realized labels, along with the modified question to make all answers in \(F(x)\) valid. After publication, evaluation is fully open and reproducible: anyone can download the benchmark and score models locally, but nobody can reconstruct the original ground truth perfectly from the capped labels (unless we hire a domain expert to solve the problem).
There are two common ways to instantiate this idea. In an obfuscation setting, you want to hide the original answer. For example, in a math benchmark, you can require a small random transformation of the correct value (e.g., “compute the answer, then add either \(+1\) or \(-1\) chosen uniformly”). In multiple-choice benchmarks, you can treat options as a circular list: first identify the true-correct option, then randomly select one of its neighbors as the published label.
The disclosure-allowed setting can be used when you are comfortable with releasing the underlying ground-truth answer, but you still want contamination to be detectable; in that case you can keep the real answer and append a random, logically irrelevant suffix from \(L\) options. This addresses a more benign threat model, where developers are not acting maliciously and leakage happens unintentionally (for example, through a subtle data-handling bug, as discussed in the GPT-3 work). As training pipelines and datasets grow in scale and complexity, deep contamination (also called semantic contamination) is also likely to become more common, and harder to detect even for the developers themselves. Later in this post, we discuss our experiments about deep contamination as well.
Note that the randomness is generated once by the benchmark creator (e.g., using Python’s random library) and then frozen,
so evaluation is deterministic. We never rely on the LLM itself to “flip a coin.”
Does capping make the benchmark too noisy to evaluate models?
If you intentionally inject randomness into labels, doesn’t the benchmark become noisy? CapBencher is not “random label noise” in the usual sense. Random label noise introduces incorrect labels, and that can absolutely blur model differences and make progress hard to track (see Vendrow et al., 2025; Gema et al., 2025). CapBencher’s labels remain logically correct under the updated question, which makes it possible to preserve model rankings in expectation.
Our theory makes this precise. Under simple assumptions, we can write the expected capped score as an increasing affine function of the model’s original score. In its simplest form, for each question \(X\), \[ s_{\text{capped}}(X) \;=\; a(X)\, s_{\text{original}}(X) \;+\; b(X), \] where \(a(X)>0\) and \(b(X)\ge 0\) are known functions of the cap level \(L(X)\) and the number of answer options \(K(X)\). This implies that if one model is better than another on the original benchmark, its expected capped score is also higher.
Because the relationship is explicit and invertible, we can go further and construct an unbiased estimator of the original accuracy from capped evaluation alone. In other words, you can publish only the capped benchmark, evaluate models openly, and still estimate what their original accuracy would have been (up to statistical uncertainty) without ever releasing the true labels.
The trade-off is the increased variance. We quantify this in the paper by deriving the exact variance of the unbiased estimator under constant \(K\) and \(L\), and we show a concrete case study. For GSM8K, the standard deviation of the accuracy estimate rises from about 0.011 (original) to about 0.027 (capped). For MMLU, it rises from about 0.003 to about 0.012. In practice, these increases are typically small relative to the accuracy gaps between successive frontier model generations, and empirically we find that model rankings remain stable (See Figure 2).
It’s worth contrasting CapBencher with a tempting naive alternative: “maybe we can just add label noise to benchmarks.” In practice, some datasets do contain mistakes, and occasionally models reach suspiciously high scores including the subsets later found to be mislabeled. This is not a reliable defense. Natural label noise is accidental and typically harms progress tracking (as we discussed earlier) because it mixes correct and incorrect supervision. CapBencher instead uses fully correct labels, and it keeps the protocol simple enough that we can do statistical testing.
Can we detect contamination in controlled experiments?
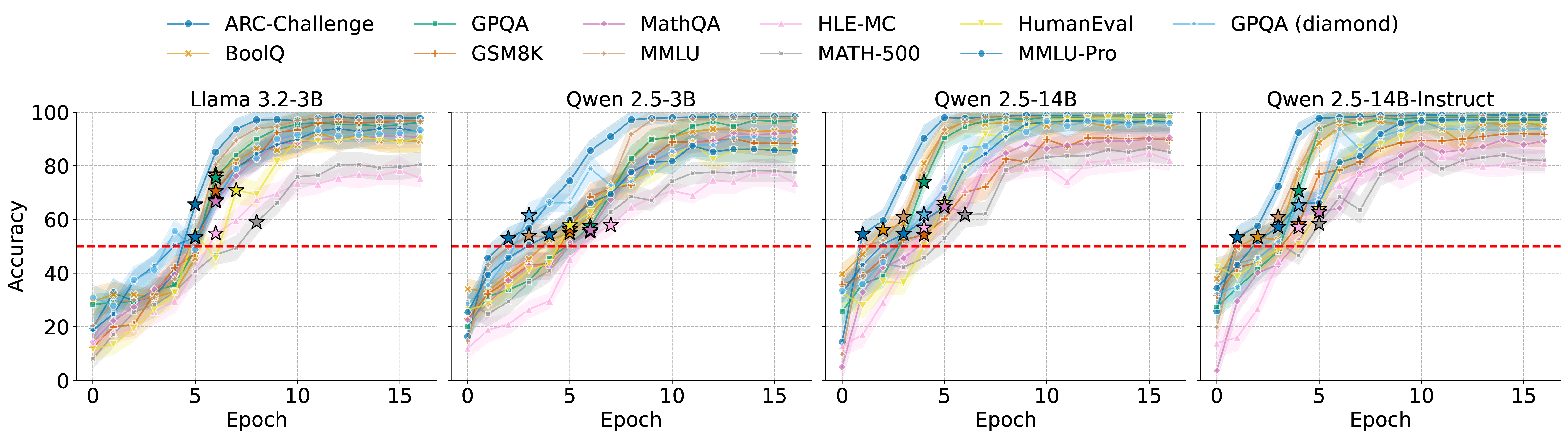
To test whether “above the cap” really behaves like a contamination signal, we run controlled experiments where we intentionally contaminate models. Concretely, we take capped benchmark data (which could plausibly leak once the benchmark is public) and perform continual pretraining on that data. We then evaluate the resulting models on the same capped benchmark. Under the intended threat model, contamination means the model has memorized the realized labels. That is exactly the situation where we expect capped accuracy to jump above the Bayes ceiling.
Empirically, this is what happens. Across families of open models (Llama, Qwen, DeepSeek) and across a diverse set of benchmarks (math, knowledge, reasoning, and code), contaminated models cross the cap and stay above it as training continues. Larger models tend to cross the cap in fewer epochs, which matches the broader observation that bigger models memorize leaked data more quickly.
Leaderboard gaming via feedback loops
Many benchmark creators keep a test set private to prevent contamination, but a private evaluation server does not eliminate overfitting. With enough queries, the score itself becomes a learning signal. This is especially concerning now that there are many automated procedures that can use an aggregated scalar feedback effectively.
In the paper we simulate a realistic “private leaderboard” setting using evolutionary model merging. We repeatedly query a capped GSM8K benchmark (cap = 50%) and optimize a merge of several base models. We never provide instance-level answers, and we only show the evaluation score. Yet after enough iterations, it finds a merged model that crosses the cap.
| Model | Accuracy (%) |
|---|---|
| Qwen 2.5-7B-Instruct | 39.87 ± 2.32 |
| DeepSeek-R1-Distill-Qwen-7B | 40.02 ± 2.01 |
| Qwen 2.5-Math-7B-Instruct | 41.02 ± 2.12 |
| Evolutionary model merging (1 + 2 + 3) | 56.52 ± 2.04* |
| * Above-cap accuracy detected with a statistical test at 5% significance in the paper. | |
This is the same pattern as contamination, but with a slightly different mechanism: the training signal is the leaderboard score rather than leaked capped answers. We cannot stop feedback loops from overfitting, but it makes them visible. Organizers are usually the benchmark creators (who knows the original ground truth), so they can use the original non-capped version as a final test, similar to how they usually have a second test set to cope with the leaderboard hacking issue.
Can we detect cross-lingual deep contamination?
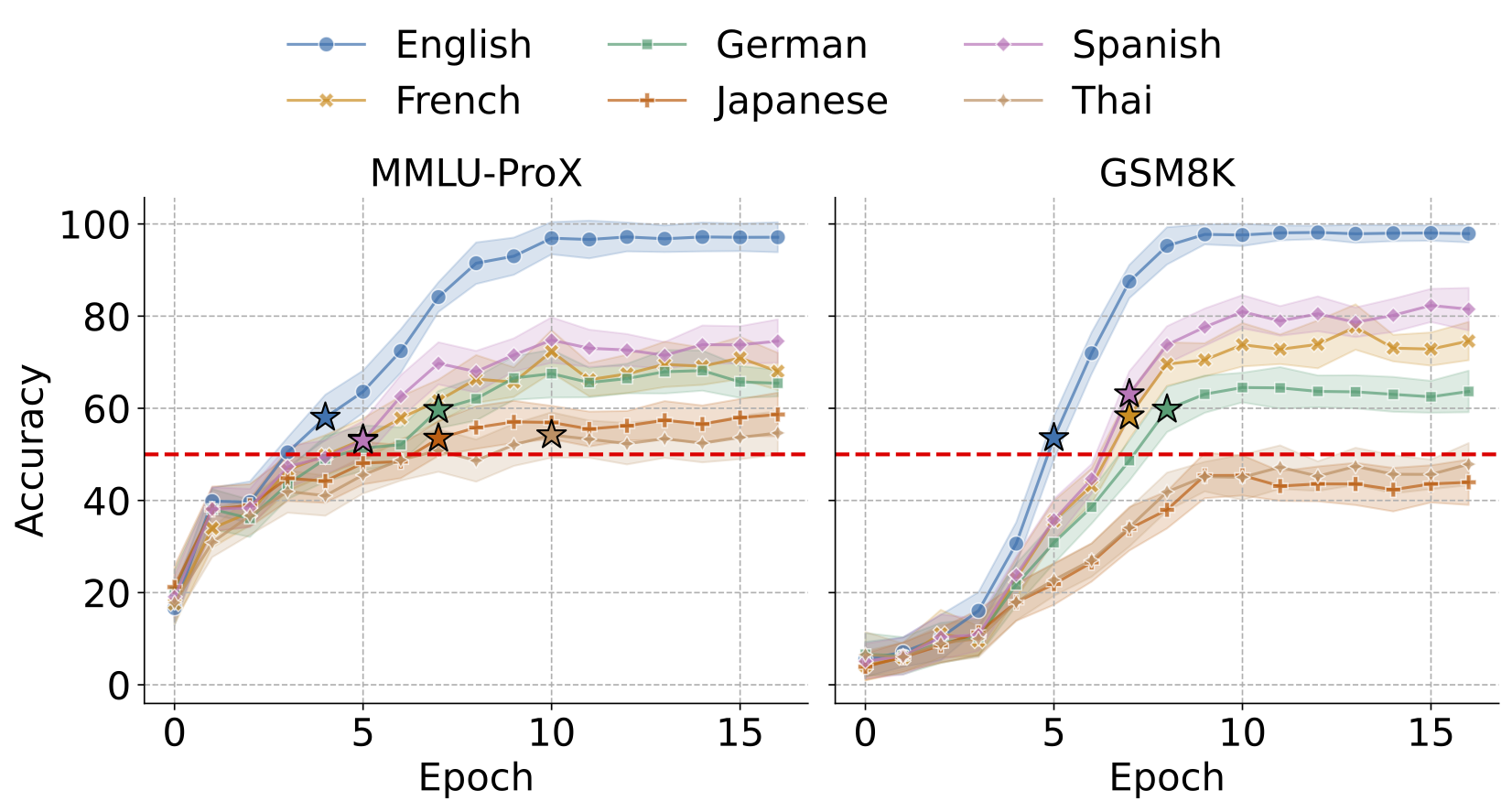
Another concern is deep contamination (which we mentioned earlier): leakage that is not verbatim reuse of benchmark text, but appears via transformations like paraphrasing or translation.
We contaminate the model in English and evaluate on six languages (English, Spanish, French, German, Japanese, and Thai) for MMLU-ProX and GSM8K. As shown in Figure 4, contamination in English not only boosts English performance but also increases accuracy in several other languages, despite no direct contamination in those languages.
Using capped data, we test whether such cross-lingual effects can be detected. We find that CapBencher identifies statistically significant cross-lingual contamination.
More results we highlight in the paper
The paper includes many additional findings, and here we highlight a few.
One concern of our methodology is reverse engineering: because the published label is a transformed version of the original answer, a strong model might try to infer the true answer from the transformation rule and the realized label. We evaluate this directly by prompting models with the randomization rule and the realized answer and asking them to recover the original answer. Reverse engineering does not help in most cases and its effectiveness drops as the cap is lowered. Importantly, even a successful reverse engineering attempt does not by itself let an attacker know whether the recovered answer is correct without access to the hidden ground truth.
We also compare against widely used and state-of-the-art contamination detection baselines, including canary-string audits, Min-k%, and Min-k%++ that are either widely used or is SoTA, but rely on model logits. Empirically we found CapBencher performs better, it is more broadly applicable (it works for black-box models), and it provides a clean statistical test rather than heuristic thresholds.
Finally, we propose an optional auditor extension to detect “partial contamination” cases where memorization inflates the capped score but not enough to exceed the Bayes accuracy; this adds a second line of defense when you can afford limited access to ground truth through a trusted evaluator.
Conclusion
Instead of treating a benchmark label set as something we must either publish (and risk contamination) or hide behind a server (and risk feedback-loop overfitting), we design the benchmark so that full correctness is intentionally unachievable without direct or indirect access to the answers. That creates an alarm that triggers when a model somehow learns the realized labels.
If you are creating a new benchmark, we think it’s worth considering capping it before you publish. CapBencher offers a practical way to keep evaluation open without giving up the ground truth (and you can always uncap it later if you want to!). Our GitHub repo and our paper includes instructions and examples on how to cap standard benchmarks. Feel free to reach out to us if you need help with capping your next benchmark.